
What is data gravity and why does it matter?
How growing datasets reshape infrastructure, costs, and long‑term architectural decisions
Takeaways
- Data gravity increases over time as datasets grow, pulling applications, compute, and supporting systems toward the data’s location and making relocation harder and more expensive.
- Centralization delivers performance benefits but also raises risks, including vendor lock‑in, dependency buildup, and architectural inflexibility.
- Backup, restore, and recovery operations are significantly affected, making regular testing and strong data governance essential for meeting recovery objectives and managing cost and complexity.
Most people don’t think about data gravity until something breaks—like a stalled restore, an unexpected cloud bill or a stalled application migration. The term has been around since 2010, but it’s still considered a niche term that is used primarily in cloud architecture, data engineering, data backup, and disaster recovery conversations.
Because data often grows exponentially and becomes harder to move, it will draw other resources toward itself. Applications, ecosystems, computing power, and infrastructure are pulled toward where the data is located. In short, data gravity is the tendency of large datasets to attract the workloads that depend on them.
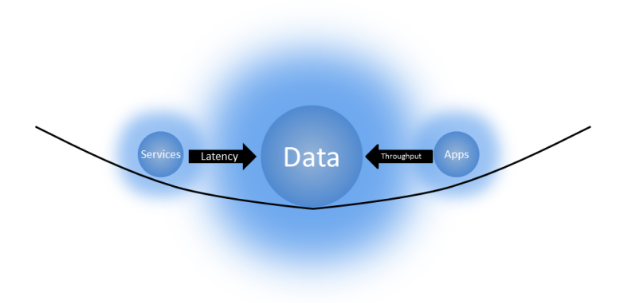
Early diagram by Dave McCrory, from his original 2010 work on the concept of data gravity. .
Over time, data becomes an anchor point. Instead of moving data to other locations, everything else moves toward the data. This is a natural outcome when considering latency and bandwidth issues, high-performance computing, real-time processing, and the benefits of ‘big data’ analytics and other use cases. Moving data off premises or out of cloud platforms introduces transfer costs and risks data exposure and operational downtime. Many companies will not consider moving data unless there is a compelling business need.
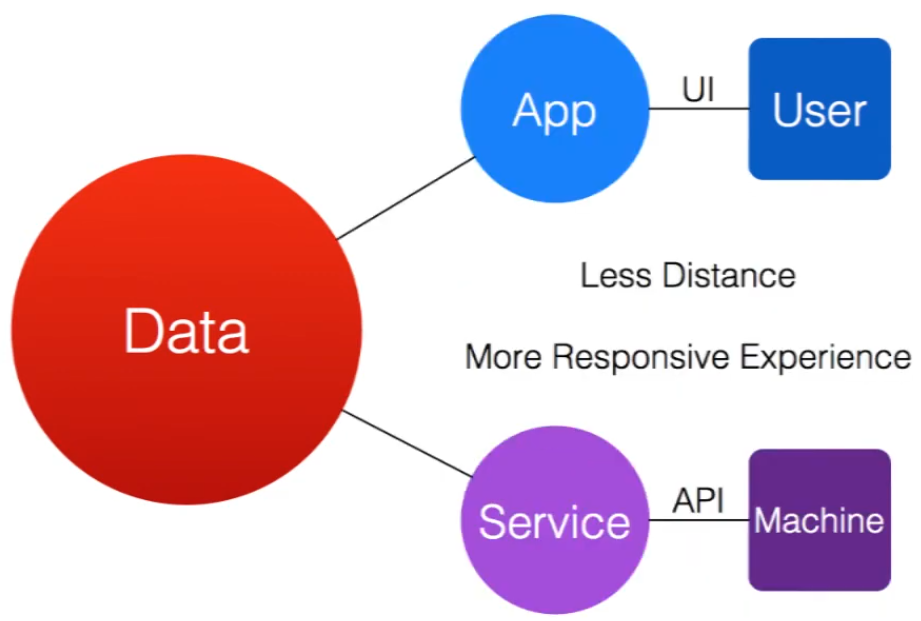
A slide taken from Dave McCrory's 2012 keynote on data gravity
While there are benefits to centralizing data and deploying applications nearby, there are also some notable drawbacks. Companies can find themselves uncomfortably dependent on a specific architecture or industry vendor. Variables like outages, price changes, and contractual or geopolitical issues can extend beyond the company’s risk tolerance. Once your dataset and applications reach a certain size, it’s a challenge to migrate away from that configuration.
The effects of data gravity might also complicate data backups. Full backups and large restores can take days if everything is being pulled across a network. Backup operators should test their backup and restore processes regularly to ensure their recovery objectives can be met. These tests should also expose bottlenecks, bandwidth issues, compliance gaps, broken dependencies, or restores that appear successful but are ultimately unusable. You may also find that you are overprotecting your low-value data or not protecting your critical data well enough.
Managing data gravity comes down to a small set of intentional acts and processes:
- Know where your data gravity exists
- Design your architecture to work with it rather than against it
- Use governance, lifecycle, and placement controls to manage costs and risk
By deliberately centralizing data only where it creates real value, companies can mitigate the negative impacts while still getting the performance and insight they need. When it’s understood and properly managed, data gravity can be used as a strategic advantage.






Subscribe to the Barracuda Blog.
Sign up to receive threat spotlights, industry commentary, and more.
