
Building Reliable Pipelines with Lakeflow Declarative Pipelines and Unity Catalog
At Barracuda, our Enterprise Data Platform team is focused on delivering high-quality and reliable data pipelines that enable analysts and business leaders across the business to make informed decisions. To drive this initiative, we’ve adopted Databricks Lakeflow Declarative Pipelines (formerly DLT) and Unity Catalog to handle our Extract, Transform, Load (ETL) workflows, enforce data quality and ensure robust governance.
Lakeflow Declarative Pipelines have empowered us to leverage our customer usage data for applications that help renewals and customer success teams deliver better customer experiences. We’ve also used Lakeflow Declarative Pipelines and Unity Catalog to create dashboards for our executive teams, enabling them to leverage data from various sources to make more informed financial decisions. These use cases rely on highly available and accurate data, for which Lakeflow Declarative Pipelines have provided significant support.
Why Lakeflow Declarative Pipelines?
Databricks’ core declarative transformation framework – embodied in Lakeflow Declarative Pipelines – allows us to define data transformations and quality constraints. This significantly reduces the operation overhead of managing complex ETL jobs and improves the observability of our data flows. We no longer have to write imperative code to orchestrate tasks; instead, we define what the pipeline should do, and Lakeflow Declarative Pipelines handles the rest. This has made our pipelines easier to build, understand and maintain.
From Batch to Streaming
Lakeflow Declarative Pipelines provides robust features to streamline incremental data processing and enhance efficiency in data management workflows. By utilizing tools like Auto Loader, which incrementally processes new data files as they arrive in cloud storage, our data team can easily handle incoming data. Schema inference and schema hints further simplify the process by managing schema evolution and ensuring compatibility with incoming datasets.
Here's how we define a streaming ingestion table using Auto Loader. This example shows advanced configuration options for schema hints and backfill settings – but for many pipelines, the built-in schema inference and defaults are sufficient to get started quickly.

Another powerful feature we’ve embraced is Lakeflow Declarative Pipelines’ support for automated Change Data Capture (CDC) using the APPLY CHANGES INTO statement. For data stored in systems like S3, incremental processing becomes seamless. This approach abstracts away the complexity of handling inserts, updates and deletes. It also ensures that our downstream tables stay in sync with source systems while maintaining historical accuracy when needed — especially when working with tools like Fivetran that deliver CDC streams. These capabilities ensure data pipelines are not only accurate and reliable but also highly adaptable to dynamic data environments.
Below is an example of a more advanced SCD1 setup — using our bronze table as the source — with schema merging and custom column filtering.


Enforcing Data Quality with Expectations
Lakeflow Declarative Pipelines Expectations allow us to test our data quality by defining declarative constraints that validate data as it flows through the pipeline. We define these expectations as Boolean SQL expressions and apply them to every dataset that we ingest. To streamline rule management, we built a custom framework that loads expectations from JSON files, making it easy to reuse rules across pipelines while keeping the codebase clean.
This is an advanced implementation that works well at our scale, but many teams could start with a few inline statements and evolve over time. Below, we show how we structure the JSON expectations and dynamically apply them during pipeline execution.

Enhancing Quarantine Tables with UDFs
While Lakeflow automatically quarantines invalid records based on expectations, we extended this functionality with a custom UDF to identify which specific rules each record violated. This approach adds a "data_quality" column to our quarantined tables, making it easier to trace and debug data issues.
This customization isn’t required for basic quarantine workflows, but it gives our team clearer visibility into why records fail and helps prioritize remediation more efficiently. Below is how we implemented this enhancement using our predefined expectation rules.

Data Quality Monitoring and Governance with Lakeflow Declarative Pipelines + Unity Catalog
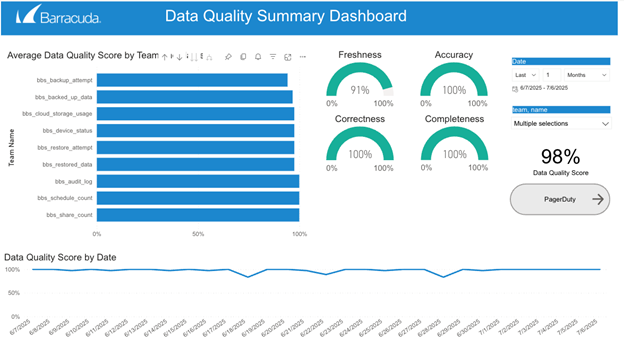
Lakeflow Declarative Pipelines automatically captures detailed runtime events through its built-in event log, including rule validations, quarantined records and pipeline execution behavior. By querying this log, we’re able to generate comprehensive data quality metrics, monitor the health of over 100 datasets and proactively detect issues before they impact downstream users.
We’ve built on this foundation by setting up real-time alerts that notify us when data fails predefined expectations or starts to deviate from normal, expected patterns. These alerts allow our team to quickly investigate anomalies and take corrective action.
Unity Catalog complements this with centralized governance, fine-grained access control and full data lineage. This combined framework enhances trust in our data, ensures consistent enforcement of quality and access policies and gives us clear visibility into the state and evolution of our data assets.
Lessons Learned and Best Practices
The implementation of Lakeflow Declarative Pipelines comes with unique constraints and evolving features that enhance developer usability and streamline operations. Initially, limitations such as the requirement for append-only sources and a single target per pipeline posed challenges. However, leveraging functionalities like schema hints and the ability to read other tables within Lakeflow Declarative Pipelines using `spark.readTable` has significantly improved flexibility. Furthermore, we’ve benefitted immensely from Lakeflow Declarative Pipeline’s data quality features. We’ve implemented more than 1,000 data quality constraints across over 100 tables. We also have data quality checks on every table in our Databricks workspace. This makes our analyst’s jobs much easier, as they are able to find, use, understand, and trust the data in our platform.
In addition to data quality and governance, there are several measurable downstream benefits for the business. Leveraging Lakeflow Declarative Pipelines has led to noticeable reductions in development time and accelerated delivery speed, while also minimizing maintenance overhead and increasing team efficiency. For example, pipelines built with Lakeflow Declarative Pipelines typically require 50% fewer lines of code than non-Lakeflow Declarative Pipelines, streamlining both development and ongoing maintenance. This efficiency has translated into faster pipeline spin-up times and more reliable support for evolving business needs. Data reliability has improved as well, enabling us to service multiple downstream use cases, such as our First Value Dashboard and Customer Usage Analytics Dashboards, across various business domains.
The introduction of the Lakeflow Pipelines IDE, where we can generate transformations as SQL and Python files and access the data preview, pipeline performance metrics and pipeline graph (all in one single view), has further increased developer velocity. The migration from HMS to Unity Catalog further refined this process, offering better visibility during pipeline execution. As Lakeflow Declarative Pipelines continue to mature, embracing these best practices and lessons learned will be essential for maximizing both data quality and operational efficiency across our platform.
Note: Sanchitha Sunil and Grizel Lopez co-authored this blog post.






Subscribe to the Barracuda Blog.
Sign up to receive threat spotlights, industry commentary, and more.
